




Google has announced a major upgrade in its artificial intelligence lineup with the introduction of Gemini 2.0, a new model designed for the agentic era. This next-generation AI brings substantial improvements in multimodality, with built-in capabilities for processing and generating images, audio, and text as well as calling external tools. The model’s advancements aim to empower AI agents to think several steps ahead and learn from various forms of input, bringing us closer to a universal assistant that can interact with information in more intuitive and powerful ways.
The announcement is accompanied by insights from top leaders in the company. The CEO of Google and Alphabet emphasized that accessible information lies at the heart of human progress, a mission that has driven the company for decades. This vision has evolved to meet the growing demands of handling diverse types of data—from text and video to images and code. Meanwhile, Google DeepMind’s executives detailed how the Gemini series builds on the success of previous multimodal models by integrating new features and enhanced performance, making it significantly more capable than earlier iterations.
Developers and early adopters are already experiencing these innovations through Gemini 2.0 Flash, an experimental version of the new model designed to deliver low latency and better performance. Gemini 2.0 Flash not only accepts multimodal input like images, video, and audio but also generates outputs that combine text with dynamic visual content and multilingual text-to-speech. In addition, it can natively call various tools such as Google Search, execute code, and interact with third-party functions. This experimental release is now available via the Gemini API in Google AI Studio and through Vertex AI, with broader deployment scheduled to follow soon.
Key highlights of the Gemini 2.0 initiative include:
- The debut of a model that represents a significant leap in multimodal and agentic AI technology.
- Enhanced performance in both speed and output versatility, including native generation of images and multilingual audio synthesis.
- Early access to Gemini 2.0 Flash for developers and trusted testers, with plans for wider consumer integration into various products.
- The introduction of innovative features like the new Deep Research tool, which leverages advanced reasoning and extended context understanding to function as a research assistant.
- A continued commitment to responsible AI development, with rigorous safety protocols and risk assessment processes in place.
In addition to the flagship release, a series of research prototypes are being showcased to explore agentic applications in various domains. For example, Project Astra is evolving to enable more natural, multilingual dialogue and improved tool integration with services such as Google Search, Lens, and Maps, as well as enhanced memory and latency performance. Project Mariner, another experimental prototype, uses Gemini 2.0 to navigate and complete complex tasks within a browser environment via an experimental Chrome extension, achieving impressive results on real-world web tasks. Furthermore, the AI-powered code agent named Jules is being trialed to assist developers directly within GitHub workflows by tackling issues and executing tasks under human supervision.
Google DeepMind is also exploring applications beyond traditional computing, including enhancements for interactive gaming experiences and even robotics. Collaborations with leading game developers are underway to test AI agents capable of understanding and responding to in-game scenarios dynamically, while other experiments are focused on applying the model’s spatial reasoning capabilities to real-world physical environments.
Underpinning these advancements is a decade-long investment in a full-stack approach to AI innovation, featuring custom hardware such as the sixth-generation TPU, Trillium, which has powered all training and inference for Gemini 2.0. This integration of cutting-edge hardware with pioneering software research has set the stage for broader deployment across Google’s suite of products—from their popular Search engine to emerging AI-driven applications.
In a commitment to building AI responsibly, the development process has incorporated multiple layers of safety measures. These include active collaboration with internal safety committees, the use of advanced AI-assisted red teaming to generate training data that mitigates potential risks, and the implementation of privacy controls that allow users to manage their interactions. Specific projects like Astra and Mariner are being meticulously refined to ensure that the agents remain under user control and are resistant to malicious inputs.
A benchmark chart below illustrates how the new model compares to its predecessors with respect to performance and functionality:
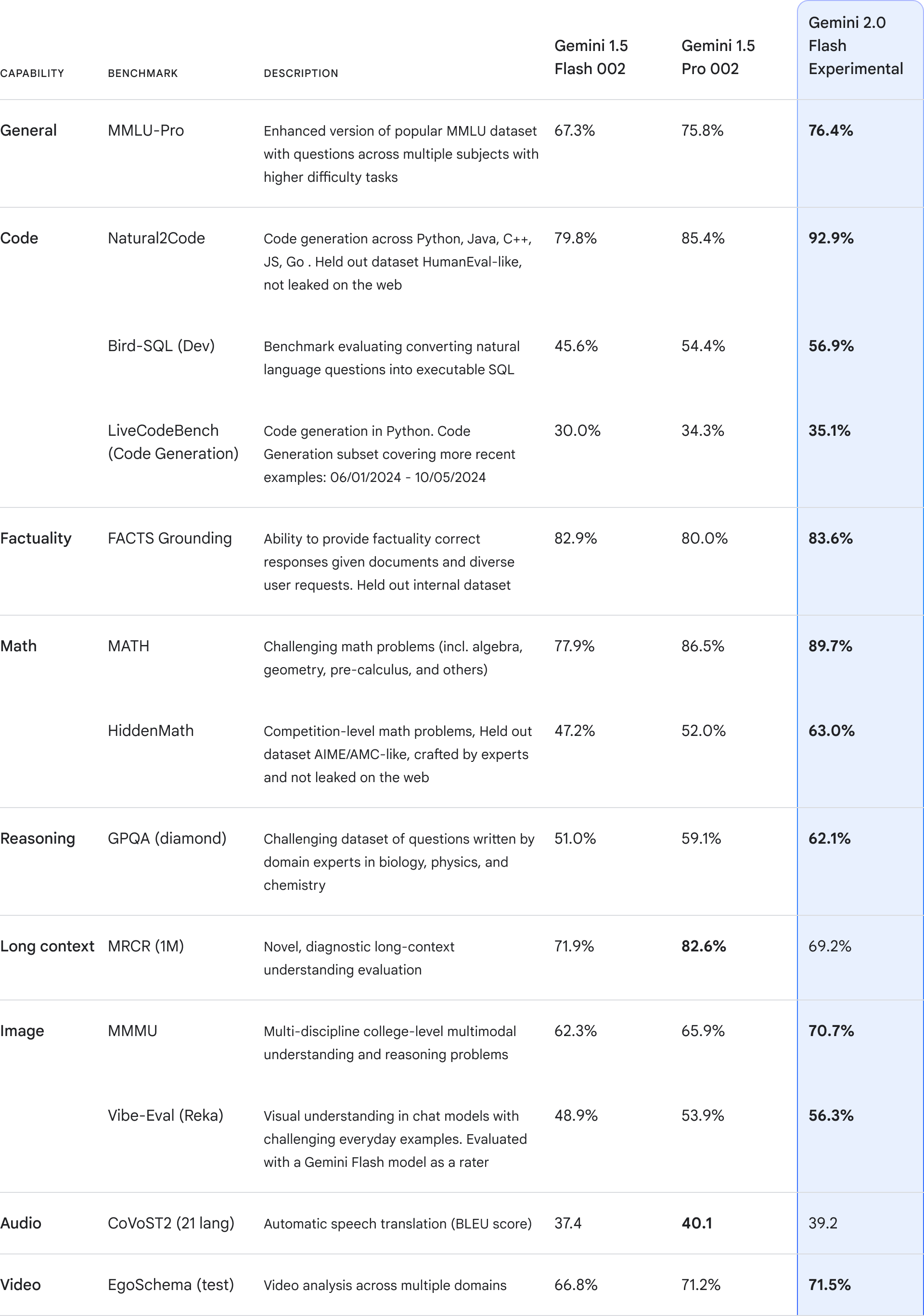
The launch of Gemini 2.0 marks a pivotal moment in AI development, opening up exciting opportunities for both developers and end users. As Google continues to integrate these advanced models into its products and explore new agentic frontiers, the promise of a more intelligent, responsive, and safe digital assistant becomes increasingly attainable.
Image credit: Latest AI news and blog posts – Google AI – Google AI

